
How to convert addresses into a Mail Merge Data Source
Article contributed by Beth Melton and Dave Rado
Suppose you are given a document of address labels in table cells, each containing one name and address:
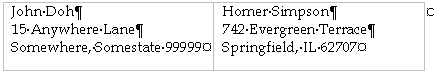
Figure 1
Although, unfortunately, you're more likely to have to work with something like the following (if you aren't familiar with non-printing characters such as ¶, you might want to read: What do all those funny marks, like the dots between the words in my document, and the square bullets in the left margin, mean?):

Figure 2
Or what if you are given a document containing addresses separated by blank paragraphs, as in:
John
W.
15
Somewhere,SomeState,
¶
Mr.
Nuclear
Springfield,
IL
Figure 3
Or a mixture of line and paragraph breaks:
John
15↵
Somewhere,SomeStateMr.
Nuclear
742
Springfield,
IL
Figure 4
Quite apart from the inconsistencies, and the unwanted spaces and so on, in the above examples, none of these formats are very helpful ways of storing data – what you really need is a Mail Merge Data Source. With that, you can easily add, delete, sort and filter records and you can use the data to create any type of mail merge document (letters, labels, faxes, emails, and so on).
If you aren't familiar with finding and replacing non-printing characters, you might want to look at Finding and replacing non-printing characters (such as paragraph marks), other special characters, and text formatting before continuing.
First find out whether a data file already exists ...
The chances are, when someone sends you a file like that, that whoever created the file originally performed a mail merge in order to create it. Ring them up and ask them. If they used a spreadsheet, or a Word datasource, you're in business – ask them to send you that. If they used a company database, ask them if they could get a CSV (comma separated variable) file exported from the database with those names and addresses. If they can get that arranged, you're in business.
But if you're stuck with having to do things the hard way, here are the steps to follow (note that whilst the Find and Replace operations described here are easy to automate – just perform them manually with the macro recorder on, then play back the macro whenever you want – other parts of the procedure are impossible to automate).
|
1. |
First, if there are any tab characters, get rid of them: press Ctrl+H to bring up the Find and Replace dialog: in the Find what box, type ^t If any tabs are replaced, click “Replace All” again until nothing is found. Once you've done that ... |
If you're starting with labels (as in Figures 1 and 2)
|
2. |
We want the address items to be separated by tabs, so ... If the address lines are separated by paragraph breaks as in Figure 1: in the Find what box, type ^p ... to replace the paragraph marks with tabs. Or if they are separated by line breaks: in the Find what box, type ^l (If a mixture of both, perform both replace operations one after the other). |
|
3. |
Now select Table/Convert Table to Text, and where it says “Separate text with”, select “Paragraph marks”. |
|
4. |
Now strip out any redundant paragraph marks: in the Find what box, type ^p^p Without closing the dialog, repeat until nothing is found. |
You will now have something like this:
John![]()
![]() W.
W.![]() Doh ➝ 15
Doh ➝ 15![]() Anywhere
Anywhere![]() Lane ➝ Somewhere,SomeState,
Lane ➝ Somewhere,SomeState,![]() 99999¶
99999¶
Mr.![]() Homer Simpson ➝ Nuclear
Homer Simpson ➝ Nuclear![]() Safety
Safety![]() Inspector ➝
Inspector ➝ ![]() 742
742![]() Evergreen
Evergreen![]() Terrace ➝ Springfield,
Terrace ➝ Springfield,![]()
![]()
![]()
![]() ➝ IL
➝ IL![]() 62707¶
62707¶
If you're starting with paragraphs (as in Figures 3 or 4)
If your paragraphs are laid out as in Figure 3:
|
2. |
Replace the double paragraph marks with $ symbols: in the Find what box, type ^p^p
|
|
3. |
Replace the remaining paragraph marks with tab characters: in the Find what box, type ^p |
|
4. |
Now replace the dollar signs with paragraph marks: in the Find what box, type $ |
If your paragraphs are laid out as in Figure 4:
|
2. |
Replace the line breaks with tab characters: in the Find what box, type ^l |
You will now have something like this:
John![]()
![]() W.
W.![]() Doh ➝ 15
Doh ➝ 15![]() Anywhere
Anywhere![]() Lane ➝ Somewhere,SomeState,
Lane ➝ Somewhere,SomeState,![]() 99999¶
99999¶
Mr.![]() Homer Simpson ➝ Nuclear
Homer Simpson ➝ Nuclear![]() Safety
Safety![]() Inspector ➝ 742
Inspector ➝ 742![]() Evergreen
Evergreen![]() Terrace ➝ Springfield,
Terrace ➝ Springfield,![]()
![]()
![]()
![]() ➝ IL
➝ IL![]() 62707¶
62707¶
Tidying up before converting to a table
Whichever of the above sets of steps you followed, you will now have a set of paragraphs, each containing fields delimited by tabs, as shown above.
At this point, you may wish to split the first name and last names into two fields, using the technique described here: Split First and Last Name.
Next we need to remove as many of the remaining anomalies as possible using Find & Replace (again, you can record these steps as a macro, and play it back whenever you want; and in the unlikely event that your data has no inconistencies in it to start with, you may be able to miss out some of these steps ).
|
1. |
Replace commas followed by a <space> with a tab character: in the Find what box, type a comma and press the spacebar
(, ) Then remove any commas that are followed by a tab: in the Find what box, type ,^t Then remove any commas that are followed by a paragraph mark in the Find what box, type ,^p Finally, replace any remaining commas (which will now be of the “Somewhere,SomeState” variety) with tabs: in the Find what box, type , |
|
2. |
Replace any double spaces with single ones: in the Find what box, press the spacebar twice Without closing the dialog, repeat until nothing is found. |
|
3. |
Replace redundant spaces at the beginning or end of a field: in the Find what box, type a <space> followed by ^t in the Find what box, type ^t followed by a <space> in the Find what box, type a <space> followed by ^p in the Find what box, type ^p followed by a <space> |
|
4. |
You may also want to replace “Mr.” with “Mr” and “Mrs.” with “Mrs”. |
You will now have something like this:
John![]() W.
W.![]() Doh ➝ 15
Doh ➝ 15![]() Anywhere
Anywhere![]() Lane ➝ Somewhere ➝ SomeState ➝ 99999¶
Lane ➝ Somewhere ➝ SomeState ➝ 99999¶
Mr.![]() Homer Simpson ➝ Nuclear
Homer Simpson ➝ Nuclear![]() Safety
Safety![]() Inspector ➝ 742
Inspector ➝ 742![]() Evergreen
Evergreen![]() Terrace ➝ Springfield ➝ IL
Terrace ➝ Springfield ➝ IL![]() 62707¶
62707¶
Converting to a table
Now begins the real nightmare ...
Select Table/Convert Text to Table, and in the dialog, choose “Separate text at Tabs”. In our example, you'll get a table like this:
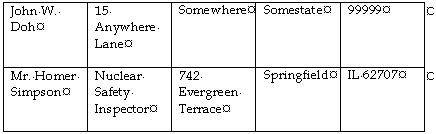
Figure 5
Although if you're incredibly lucky, you might have something more like this:
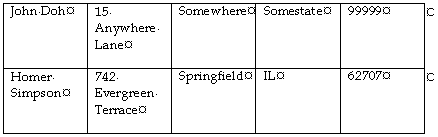
Figure 6
Splitting the columns where necessary
|
1. |
You can split the First name and Surname into separate columns as follows:
|
||||||||||||
|
2. |
The same principle can be used to split any other columns that need splitting up; for instance, if you have City, State, Zip in one column. |
||||||||||||
|
3. |
Next, insert any additional columns that may still be needed; for example, in Figure 5, you would need to add a column to cater for the JobTitle field. |
||||||||||||
|
4. |
Insert a new row 1, and add the appropriate field names, giving you something like this:
|
||||||||||||
|
5. |
You may need to make the page landscape in order to see it all in Page/Print Layout View. You may also want to select the top row and select Table/Headings (Word 97), or Table/Heading Row Repeat (Word 2000 and above), so that the top row will appear at the top of every page. |
||||||||||||
|
6. |
Finally, (and if you have a large amount of data, this is often the most time-consuming part of the entire procedure), drag and drop the data into the correct columns; so that you end up with something like this:
(In the process of doing so, you may find that you still don't have enough columns – but you can add an extra column at any stage). |


You should now have a table that can be used as a mail merge data source. If it contains a large number of rows, you can paste it straight into Excel, which will give you much better performance.